The Downfall of Polymarket’s Data Indexing
Summary
Welcome to the GCC Research column’s “Tragedy of the Crypto Commons” series.
This series delves into the critical, yet increasingly ignored, public goods that underpin the crypto ecosystem. These foundational infrastructures often face insufficient incentives, governance challenges, or a drift toward centralization. The clash between crypto’s ideals and the need for redundancy and resilience is being tested in these overlooked areas.
In this installment, we spotlight one of the highest-profile applications in the Ethereum ecosystem: Polymarket and its data indexing tools. This year alone, controversies around Trump’s election odds, oracle manipulation in Ukrainian rare earth trades, and political side bets like Zelensky’s suit color have repeatedly put Polymarket at the center of public debate. The platform’s market significance and the capital at stake have amplified the impact of these disputes.
But for a platform that represents “decentralized prediction markets,” is its core infrastructure—data indexing—truly decentralized? Why hasn’t public infrastructure like The Graph lived up to expectations? And what would a truly robust, sustainable public good for data indexing look like?
I. A Chain Reaction: The Fallout from a Centralized Data Platform Outage
In July 2024, Goldsky—a real-time blockchain data infrastructure platform serving Web3 developers with indexing, subgraph, and streaming data services—suffered a six-hour outage. This incident crippled a large portion of the Ethereum ecosystem: DeFi frontends couldn’t show user positions or balances, Polymarket displayed incorrect data, and countless projects appeared completely unusable from the end user’s perspective.
Such a failure should be unthinkable in a truly decentralized application ecosystem. After all, isn’t the core aim of blockchain technology to eliminate single points of failure? The Goldsky incident reveals an unsettling truth: while the blockchain layer may be decentralized, the infrastructure that powers on-chain apps often depends on centralized services.
The reason is simple: blockchain data indexing and retrieval are “non-excludable, non-rivalrous” digital public goods. Users expect these services to be free or extremely low cost, yet they require continual investment in hardware, storage, bandwidth, and operational expertise. Without a sustainable business model, a winner-take-all dynamic emerges—if one provider achieves a lead in speed or capital, developers route all traffic through them, recreating a single point of dependency. As projects like Gitcoin have often pointed out, “Open-source infrastructure can generate billions in value, but creators often still can’t pay the mortgage.”
This should serve as a wake-up call: the decentralized world urgently needs public goods funding, redistribution, or community-driven solutions to create diverse Web3 infrastructure—or centralization will reassert itself. We call on DApp developers to build local-first products and urge the technical community to account for data retrieval outages, ensuring users can interact with projects even if indexing services go down.
II. Where Does DApp Data Really Come From?
To understand incidents like Goldsky’s outage, let’s look at how DApps work behind the scenes. For most users, a DApp means two things: an on-chain contract and a frontend web interface. People check transaction status with tools like Etherscan, get updates and interact with contracts through the frontend. But where does all the information on the frontend actually originate?
Why Data Retrieval Services Are Essential
Consider a scenario where you’re building a lending protocol that needs to show users their positions, collateral, and debt. Intuitively, you might think the frontend can grab this directly from the blockchain. In practice, however, lending protocols don’t allow address-based queries for position data—only position IDs can be used. Showing a user’s positions requires scanning every position in the system and filtering for ownership—a task akin to sifting through millions of ledger pages by hand. While technically possible, it’s painfully slow and inefficient. For large DeFi protocols, even server-based local-node queries can take hours.
This is why infrastructure like Goldsky exists—to enable faster data access through indexing services. The figure below shows how these services structure and deliver data to applications.

At this point, you might ask: Doesn’t Ethereum already have a decentralized data retrieval platform, The Graph? How does it relate to Goldsky, and why do so many DeFi projects opt for Goldsky over the seemingly more decentralized The Graph?
The Graph, Goldsky, and SubGraph: How Are They Connected?
Let’s clarify some technical terms:
- SubGraph is a development framework for extracting and aggregating on-chain data for frontend consumption.
- The Graph is an early decentralized data retrieval platform. It created the SubGraph framework in AssemblyScript, letting developers write code to capture contract events and store them in databases, accessible via GraphQL or even SQL.
- Those who host and run SubGraph-based services are called “SubGraph operators.” Both The Graph and Goldsky act as SubGraph hosts, since SubGraph programs need to be operated on servers. This is reflected in Goldsky’s documentation:
Why are there multiple SubGraph operators?
Because the SubGraph framework only defines how data is extracted and written, not how it ultimately flows or where it’s stored. Each operator implements their own strategy for data flow and infrastructure.
Operators often enhance node setups for speed and reliability. Different providers—The Graph, Goldsky, etc.—have their own technical and business approaches.
Currently, The Graph employs Firehouse technology, which has greatly improved performance, while Goldsky hasn’t open-sourced its core operational code.
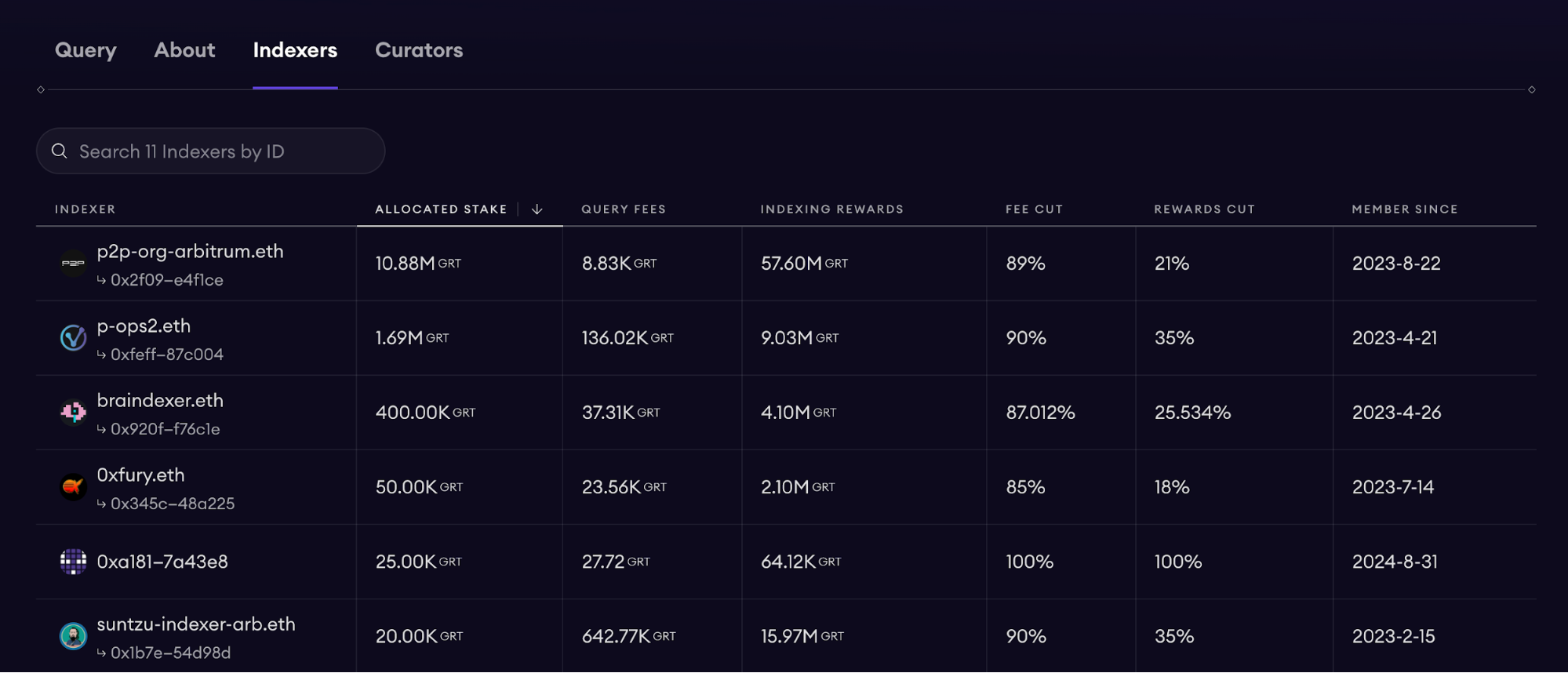
Essentially, The Graph is a decentralized data retrieval hub. For example, the Uniswap v3 subgraph lists many operators serving Uniswap v3, making The Graph a “marketplace” of SubGraph operators ready to process data queries for submitted subgraph code.
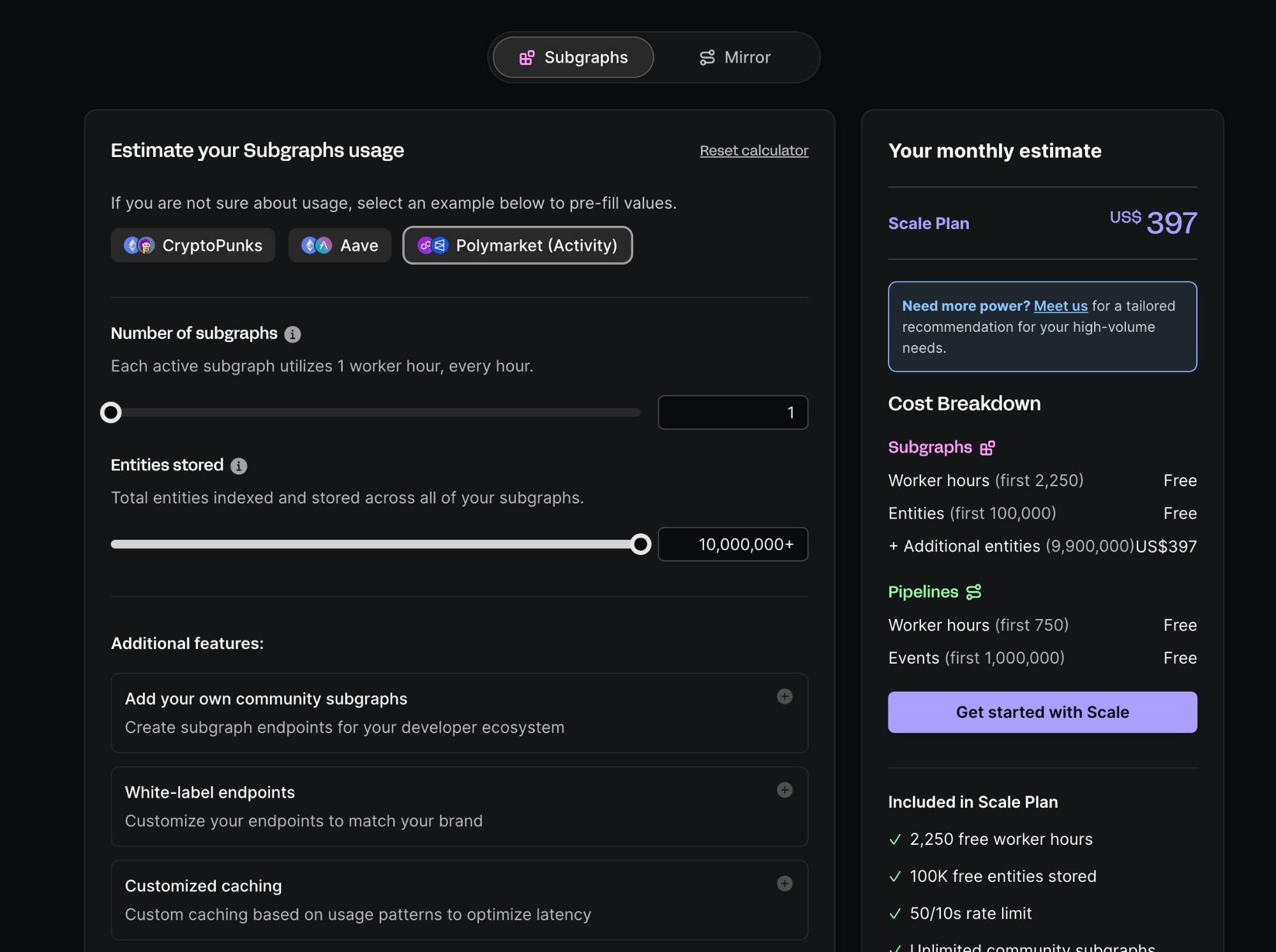
Goldsky’s Pricing Model
As a centralized SaaS offering, Goldsky uses a simple, resource-based pricing model, familiar to most tech professionals. Here’s Goldsky’s pricing calculator interface:
The Graph’s Pricing Model
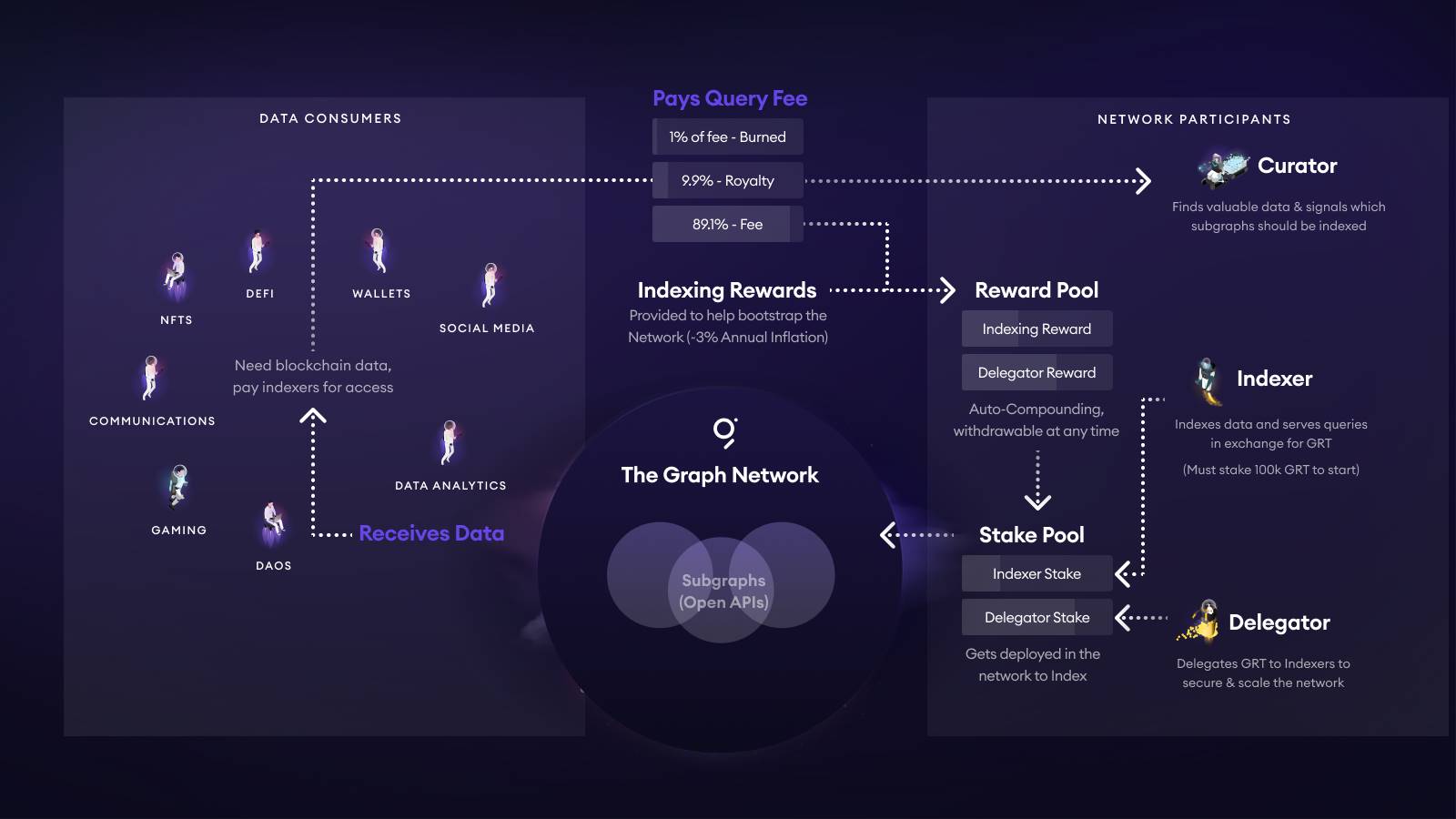
The Graph operates differently, using GRT tokenomics for its pricing. Here’s an overview of its fee structure:
- When a DApp or wallet queries a SubGraph, the fee is split: 1% burned, about 10% to the curator pool (for curators or developers), and ~89% to Indexers and Delegators via incentives.
- To become an Indexer, you need to stake at least 100,000 GRT; providing incorrect data can result in slashing. Delegators delegate GRT to Indexers and share the 89% reward pool proportionally.
- Curators (generally developers) signal their SubGraph’s value by staking GRT—more signals attract more resources from Indexers. Community experience suggests self-staking 5,000–10,000 GRT secures prompt service from several Indexers. Curators also receive the 10% royalty.
The Graph’s query fee:
After registering an API key, developers pay based on the number of queries, funded in advance with GRT tokens.
The Graph’s curation staking fee:
To encourage Indexer support, SubGraph deployers must signal (stake) GRT on their projects. The more GRT staked, the more likely Indexers are to participate. Historically, operators only engage once a threshold (often ~10,000 GRT) is reached.
During testing, The Graph provides a free quota on its official infrastructure, but this is not for production use. Once ready, the SubGraph can be published to the public network for Indexers to compete for curation and indexing—there’s no way to pay a specific operator directly. The process uses GRT staking, and only when enough GRT is committed do Indexers join in.
Poor Developer and Accounting Experience
For most developers, The Graph can be a headache. Buying GRT is easy in the Web3 world, but the curation and Indexer engagement process is slow and unpredictable. Two main pain points:
- Uncertainty in how much GRT to stake or how long it takes Indexers to engage. The author has personally had to consult The Graph’s community for advice; most developers lack clear guidance, and there’s a lag even after staking.
- Accounting complexity. The token-based billing model complicates cost tracking, and enterprise accountants often have no framework for classifying these expenses.
Centralization: The Devil You Know?
For most developers, Goldsky offers the path of least resistance: predictable, easy-to-understand pricing and instant access after payment. This leads to heavy dependence on a single indexing provider.
The complexity of The Graph’s tokenomics has hampered widespread adoption. Token models can be complex, but that complexity shouldn’t be forced onto users; for instance, the curation and staking mechanics should be hidden behind a streamlined payment interface.
This isn't just the author’s view. Well-known smart contract engineer and Sablier founder Paul Razvan Berg has publicly criticized The Graph’s user experience for SubGraph publishing and GRT billing.
III. What Solutions Currently Exist?
How do you resolve single points of failure in data retrieval? As described above, developers can use The Graph, but the process is complicated—buy GRT, stake it for curation, pay API fees.
There’s a rich landscape of EVM indexing tools. For an overview, check Dune’s The State of EVM Indexing or rindexer’s indexing software roundup. A contemporary debate can be found here.
This article doesn’t detail the cause of Goldsky’s outage. According to Goldsky’s own report, they know the cause but will only share details with enterprise customers; third parties can only speculate. The report suggests a database access issue after data was retrieved, only resolved through AWS support.
Here are some alternative solutions:
- ponder: a simple, developer-friendly indexing solution that’s easy to deploy and can be self-hosted on rented servers.
- local-first: a design philosophy advocating resilient user experiences even when network connectivity is interrupted. For blockchain, this means relaxing requirements so users can still access essential functionality when connected to the chain.
ponder
Why does the author recommend ponder?
- No vendor lock-in. Ponder began as an individual’s project, so there’s no supplier dependency; you just provide an Ethereum RPC URL and a Postgres database link.
- Excellent developer experience. It’s written in TypeScript, mainly using the viem library, making it ergonomic for modern developers.
- Superior performance.
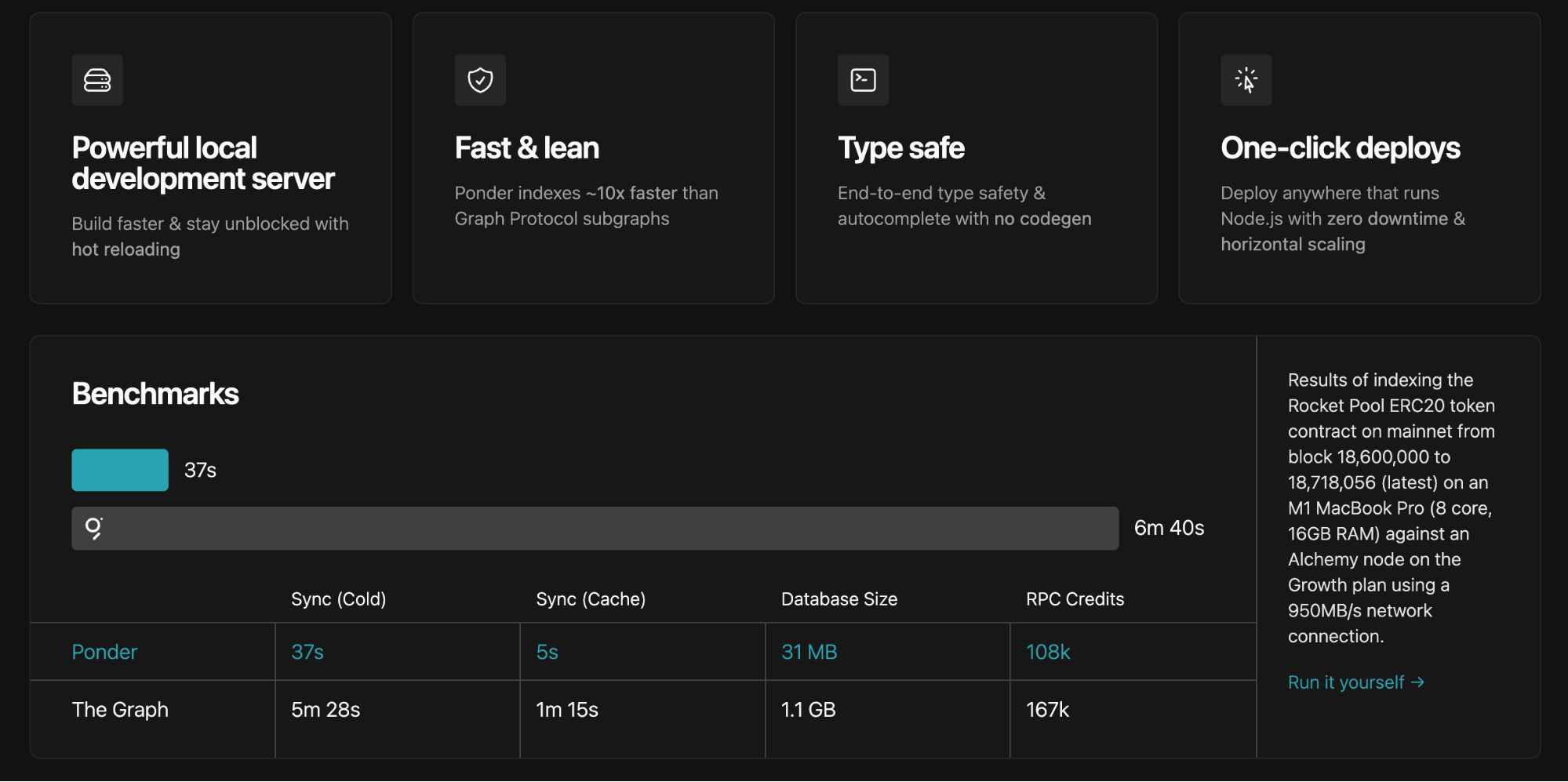
Still, ponder is evolving rapidly, and breaking changes can disrupt previous deployments. This article isn’t a technical intro, so technical readers should consult the official docs for details.
Ponder’s emerging commercialization strategy is worth noting and connects to the “isolation theory” referenced in prior discussions.
Briefly, “isolation theory” holds: Public goods can, in principle, serve unlimited users. Any attempt to charge excludes some, reducing overall welfare (“not Pareto optimal”). Discriminatory pricing for individuals is usually too costly. Thus, public goods are free not by necessity, but by the reality that charging is inefficient. Isolation theory suggests that by separating a homogeneous group of users, only they can be charged, leaving the good freely available to others.
Here’s how ponder applies isolation theory:
- Deploying ponder requires technical skills—developers must provide their own RPC and database.
- Once running, ongoing management is needed (like using a proxy for load balancing), making it less approachable for beginners.
- Ponder is piloting a one-click deployment option via marble—just submit code for automated deployment.
In other words, less technical or less motivated users are “isolated” and can pay for managed services, while others can always use and self-host ponder for free if desired.
Ponder vs. Goldsky—Who Chooses What?
- Ponder, with zero vendor dependency, is more common for small projects.
- Larger projects tend to prefer Goldsky or similar services for better performance and reliability guarantees.
Both approaches have risks. The recent Goldsky incident shows that maintaining a backup self-hosted ponder instance is smart. With ponder, watch out for invalid RPC responses—safe recently reported an indexer crash caused by bad RPC data (case here). While there is no direct evidence Goldsky’s outage resulted from this, the author suspects a similar cause.

The “Local-First” Approach
“Local-first” development has gained attention in recent years. In essence, local-first apps:
- Function offline
- Enable cross-device collaboration
Most local-first strategies involve CRDTs (Conflict-free Replicated Data Types), a kind of distributed data structure that enables automatic conflict resolution and eventual consistency—think of it as a lightweight consensus mechanism.
For blockchain, strict local-first requirements can be relaxed. The minimum bar: ensure that, even if indexers are down, users still have basic access to their data via the frontend. The blockchain itself already handles multi-client coordination.
For DApps, local-first can be engineered as follows:
- Cache vital data: Store important information—balances, positions, etc.—locally so users always see their latest data, even if indexers fail.
- Graceful fallback: If backend services go down, switch to direct RPC calls to query the chain, delivering core functionality as long as users are online.
This design makes apps much more resilient; otherwise, outages make apps unusable. The ultimate local-first approach would have users run their own full nodes and retrieve data using tools like trueblocks. For more on decentralized or local indexing, see this discussion.
IV. Conclusion
The six-hour Goldsky outage was a wake-up call. While blockchain is inherently decentralized and designed to avoid single points of failure, the application stack remains highly dependent on centralized infrastructure, creating systemic vulnerabilities.
This article explained why established decentralized retrieval services like The Graph haven’t become mainstream, spotlighting the friction introduced by GRT’s tokenomics. We explored how to build more resilient data retrieval infrastructure—such as using self-hosted frameworks like ponder as a fallback—and highlighted ponder’s pragmatic commercialization path. We also introduced the local-first model and encouraged developers to build apps that work even when indexing services are unavailable.
Web3 developers have increasingly recognized the dangers of single points of failure in data retrieval. GCC urges builders to pay attention to this vital layer and experiment with decentralized retrieval or frontends that keep DApps usable when data services break down.
Disclaimer:
- This article is reprinted from TechFlow, with copyright belonging to the original author shew. For any issues with this reprint, please contact the Gate Learn team; we will address them promptly according to our procedures.
- Disclaimer: All opinions and views expressed herein are those of the author and do not constitute investment advice.
- Other language versions are translated by the Gate Learn team. Unless Gate is clearly cited, do not copy, redistribute, or plagiarize these translations.
Related Articles

Solana Need L2s And Appchains?

The Future of Cross-Chain Bridges: Full-Chain Interoperability Becomes Inevitable, Liquidity Bridges Will Decline

Sui: How are users leveraging its speed, security, & scalability?

Navigating the Zero Knowledge Landscape

What Is Ethereum 2.0? Understanding The Merge
